- Definition: XQuery is a query language designed for querying collections of XML data. It is a standardized language developed by the W3C (World Wide Web Consortium) for querying and extracting information from XML documents.
- Syntax: XQuery syntax resembles SQL (Structured Query Language) but is specifically tailored for XML data. It allows users to retrieve, manipulate, and transform XML data using a set of expressive query constructs.
- Use Cases:
- XML Data Retrieval: XQuery is primarily used for extracting specific information from XML documents. This can include retrieving elements, attributes, or entire subtrees based on certain criteria.
- Data Transformation: XQuery supports transformations of XML data into different formats. It enables the conversion of XML documents into other XML formats, HTML, JSON, or plain text.
- XML Data Manipulation: XQuery facilitates the modification of XML data. It allows for the insertion, deletion, and updating of elements and attributes within XML documents.
- Integration with XML Databases: XQuery is often used with XML databases for efficient querying and management of XML data.
- Web Services: XQuery can be utilized in web services to query XML data and transform it according to the requirements of clients.
- XML Publishing: XQuery can be employed to extract data from XML sources and publish it in various formats for consumption by different applications.
- Benefits:
- Declarative Language: XQuery follows a declarative approach, where users specify what data they want to retrieve or manipulate without needing to specify how to achieve it. This abstraction simplifies query development.
- Expressiveness: XQuery provides powerful constructs for querying and transforming XML data, enabling users to express complex operations concisely.
- Standardization: Being a W3C standard, XQuery ensures interoperability across different systems and platforms that support XML.
- Efficiency: XQuery queries are optimized for processing XML data efficiently, providing good performance even with large datasets.
- Integration: XQuery can be seamlessly integrated with other XML technologies such as XPath, XSLT, and XML Schema, allowing for comprehensive XML data processing solutions.
Java APIs for XQuery:
Java provides several APIs for working with XQuery:
- XQJ (XQuery API for Java): This is a standard API for executing XQuery from Java programs. It provides interfaces and classes for compiling, executing, and processing XQuery expressions within Java applications. Some popular implementations of XQJ include:
- Saxon XQJ
- BaseX XQJ
- Oracle XQuery for Java (XQJ)
- JAXP (Java API for XML Processing): While not specifically designed for XQuery, JAXP provides facilities for parsing and manipulating XML documents in Java. It includes interfaces for XPath evaluation, which can be utilized for executing XPath expressions within XQuery.
- Java XQuery Engines: Some Java-based XQuery engines offer APIs for integrating XQuery processing directly into Java applications. Examples include:
- Saxon XQuery
- BaseX Java API
- eXist-db Java API
- Third-party Libraries: There are various third-party libraries available for XQuery processing in Java, offering additional functionalities and features. These libraries may provide their own APIs for executing XQuery. Examples include:
- Apache Jena
- XMLBeans
Using these Java APIs, developers can seamlessly integrate XQuery processing capabilities into their Java applications, enabling efficient querying and manipulation of XML data.
In our blog we will first install BaseX tool that provide app that we can use for querying the xml directly.
You can download the BaseX tool from below locations.

Now lets create one simple xls which we will use in our exercise.
1- course.xml
<?xml version="1.0" encoding="UTF-8"?>
<courses>
<course category="JAVA">
<title lang="en">Learn Java in 3 Months.</title>
<trainer>Sonoo Jaiswal</trainer>
<year>2008</year>
<fees>10000.00</fees>
</course>
<course category="Dot Net">
<title lang="en">Learn Dot Net in 3 Months.</title>
<trainer>Vicky Kaushal</trainer>
<year>2008</year>
<fees>10000.00</fees>
</course>
<course category="C">
<title lang="en">Learn C in 2 Months.</title>
<trainer>Ramesh Kumar</trainer>
<year>2014</year>
<fees>3000.00</fees>
</course>
<course category="XML">
<title lang="en">Learn XML in 2 Months.</title>
<trainer>Ajeet Kumar</trainer>
<year>2015</year>
<fees>4000.00</fees>
</course>
</courses>
Lets try to play with Xquery syntex with this newly created course.xml and check if we are getting the desire output.
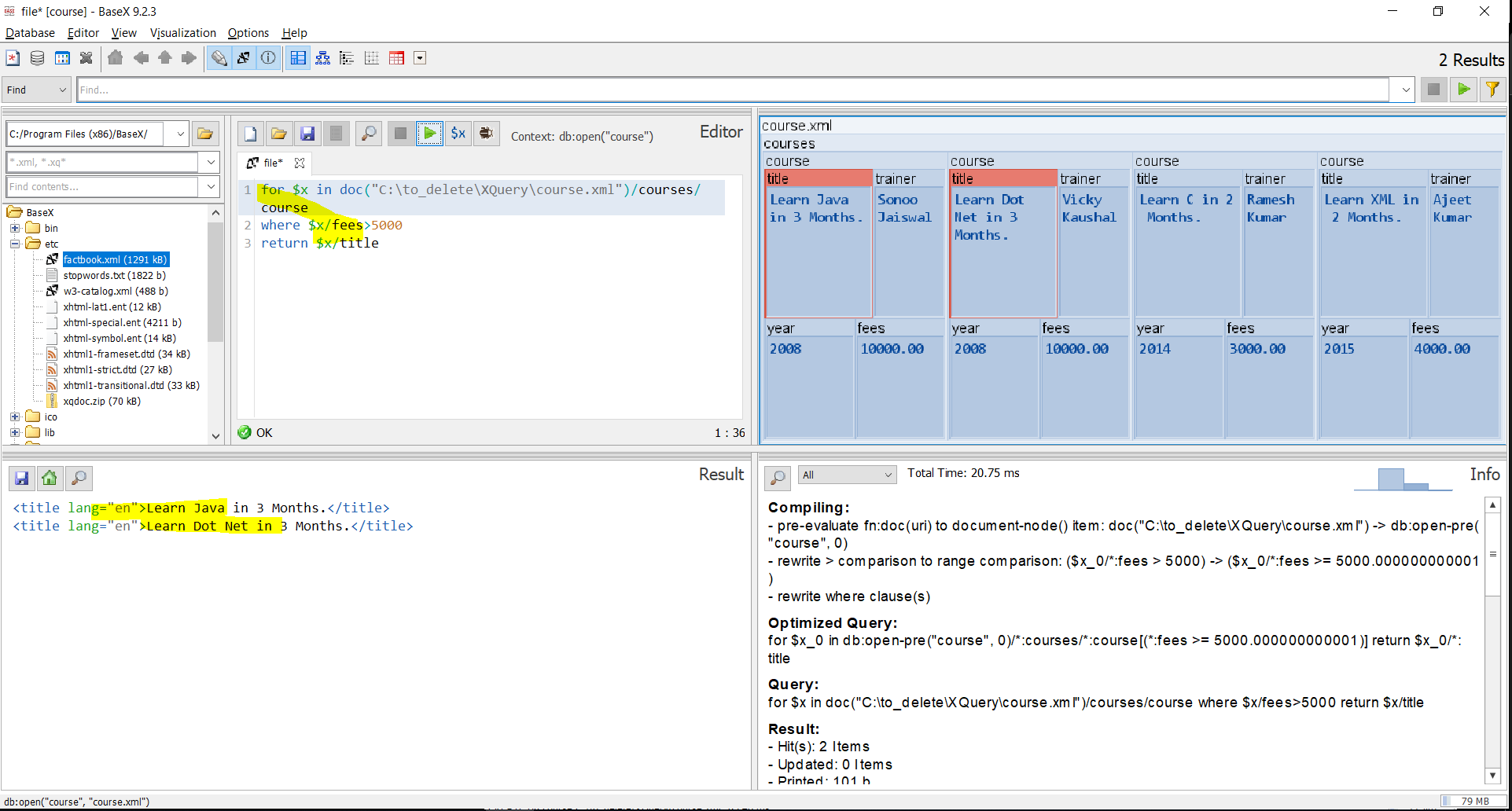
Now lets create a xquery yml as given below
2- courses.xqy
let $courses := (doc("course.xml")/courses/course)
return <results>
{
for $x in $courses
where $x/fees>2000
order by $x/fees
return $x/title
}
</results>
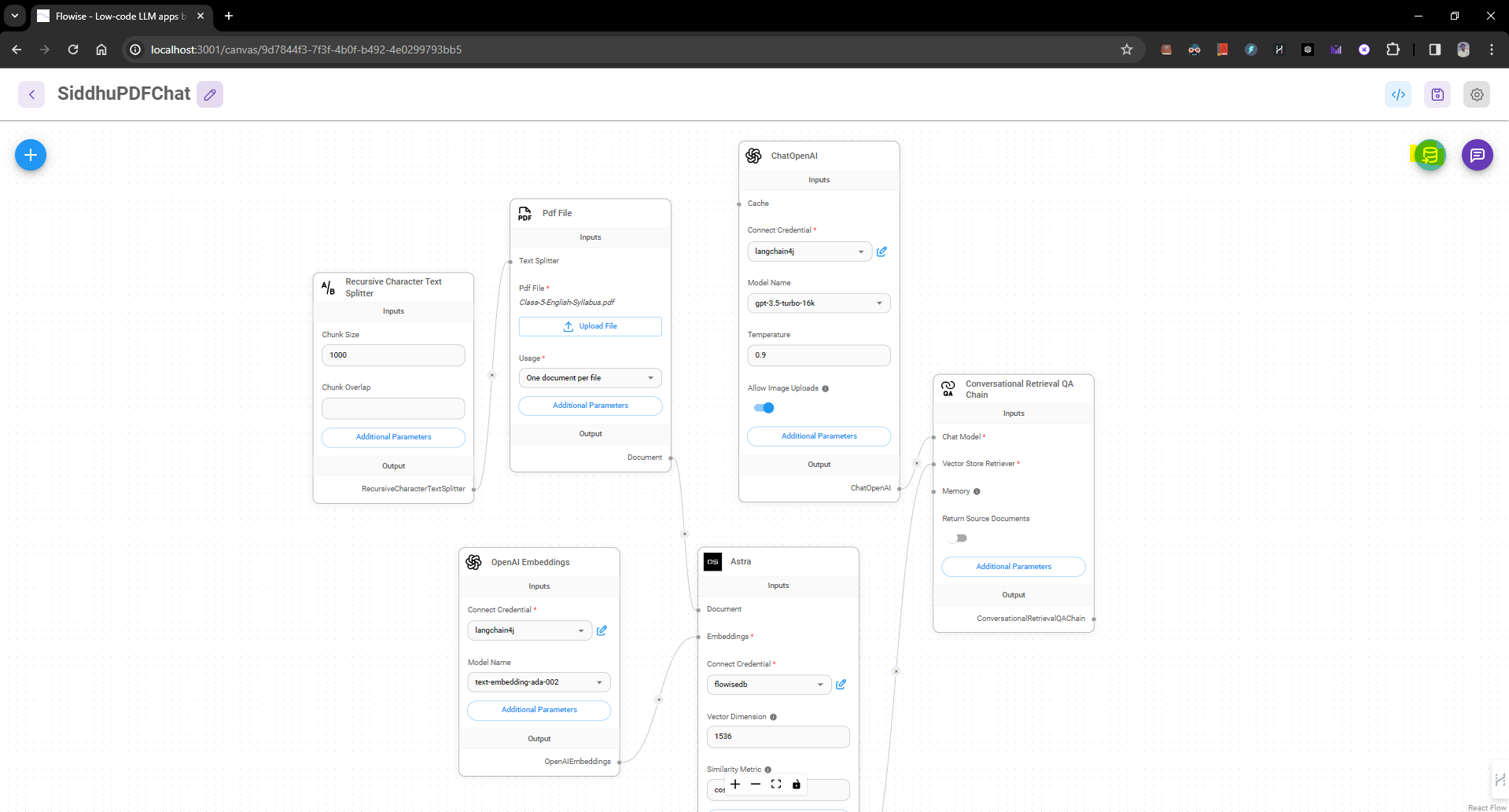
Now lets try to execute our courses.xqy by using our maven project.
create a maven project using below command
mvn archetype:generate -DgroupId=com.mycompany -DartifactId=siddhuxqueryapp -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Lets open that project in STS IDE and add below given package to consume Xquery file
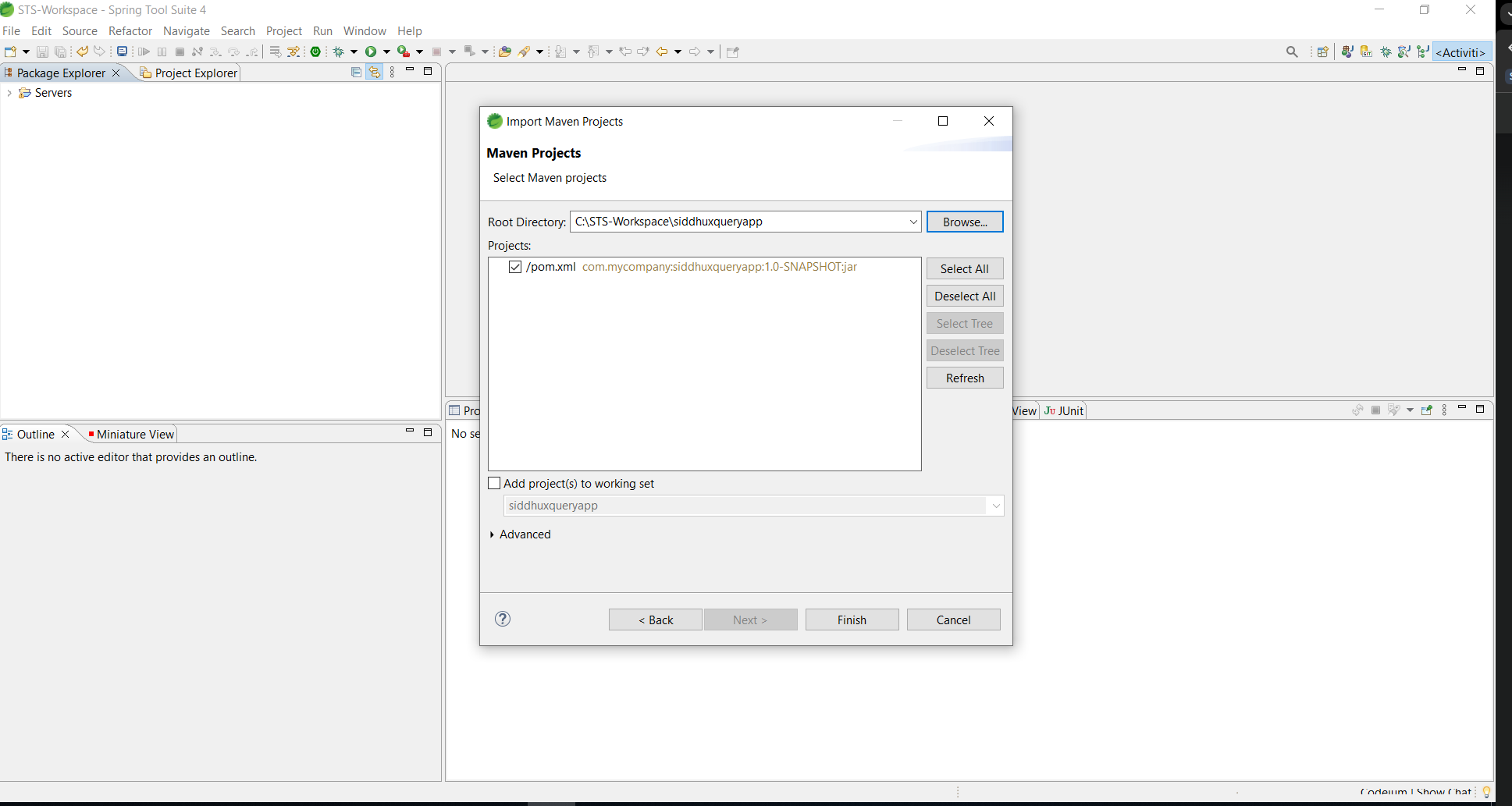
and following dependencies init.
3- Maven entry
<dependencies>
<!-- Saxon HE -->
<dependency>
<groupId>net.sf.saxon</groupId>
<artifactId>Saxon-HE</artifactId>
<version>10.6</version>
</dependency>
</dependencies>
4- Lets keep the course.xml and our courses.xqy in our resource folder where our java files is present
5- XQueryConsumer.java
package com.mycompany;
import java.io.File;
import net.sf.saxon.s9api.DocumentBuilder;
import net.sf.saxon.s9api.Processor;
import net.sf.saxon.s9api.XQueryCompiler;
import net.sf.saxon.s9api.XQueryEvaluator;
import net.sf.saxon.s9api.XQueryExecutable;
import net.sf.saxon.s9api.XdmItem;
import net.sf.saxon.s9api.XdmNode;
import net.sf.saxon.s9api.XdmValue;
public class XQueryConsumer {
public static void main(String[] args) throws Exception {
Processor processor = new Processor(false); // Use false for Saxon-HE
DocumentBuilder documentBuilder = processor.newDocumentBuilder();
XdmNode sourceDocument = documentBuilder.build(new File("C:\\STS-Workspace\\siddhuxqueryapp\\src\\main\\resources\\course.xml"));
XQueryCompiler compiler = processor.newXQueryCompiler();
XQueryExecutable executable = compiler.compile(new File("C:\\STS-Workspace\\siddhuxqueryapp\\src\\main\\resources\\courses.xqy"));
XQueryEvaluator evaluator = executable.load();
evaluator.setContextItem(sourceDocument); // Set the source document as the context item
// Set any other execution options as needed
XdmValue result = evaluator.evaluate(); // Execute the query
for (XdmItem item : result) {
System.out.println(item.getStringValue());
}
}
}


You can download the project from given below git location.
https://github.com/shdhumale/siddhuxqueryapp.git
Summary:-
- 💡 XQuery is a query language for XML data developed by W3C.
- 💡 Its syntax resembles SQL but is tailored for XML data manipulation.
- 💡 Use cases include XML data retrieval, transformation, manipulation, integration with databases, web services, and publishing.
- 💡 Benefits include declarative approach, expressiveness, standardization, efficiency, and integration with other XML technologies.
- 💡 Java provides APIs like XQJ and JAXP for XQuery processing.
- 💡 Java XQuery engines and third-party libraries offer additional functionalities.
- 💡 Developers can integrate XQuery processing into Java applications efficiently.
- 💡 The blog provides examples and resources for practicing XQuery in Java development.